- Published on
【论文分享】|Attention Sink 何时出现在语言模型中?
- Authors

- Name
- 娄司宇
- GitHub
- @LLSGYN
论文链接:[ICLR 2025] WHEN ATTENTION SINK EMERGES IN LANGUAGE MODELS: AN EMPIRICAL VIEW
Github 仓库:https://github.com/sail-sg/Attention-Sink
什么是 Attention Sink?
在 LLM 计算时,经常会为一些特定的 token 位置分配非常高的 attention score,从而在这些 token 位置形成垂直的 attention pattern。最常见的位置就是首 token,可以形式化表达为

已有一些工作尝试理解 attention sink 存在的原因,并尝试给出相关解释:
- StreamingLLM:initial tokens are visible to almost all subsequent tokens because of the autoregressive language modeling nature, making them more readily trained to serve as attention sinks.
Attention Sink 的特性
一、首 token 的特性
因此
计算特性:
以及相应的 Q、K、V 可以视为直接从 word embedding 得到的 MLP 输出。 - 首 token 和其他后续的 token 计算有一个显著不同:第一个 hidden state 的计算不涉及 self-attention
, 。
- 首 token 和其他后续的 token 计算有一个显著不同:第一个 hidden state 的计算不涉及 self-attention
数值特性:从特定层开始,
的 范数会显著大于其他 token 。 key, value 数值:第一个 token 的 key/value
范数显著小于同一图中其他 token 的对应值。
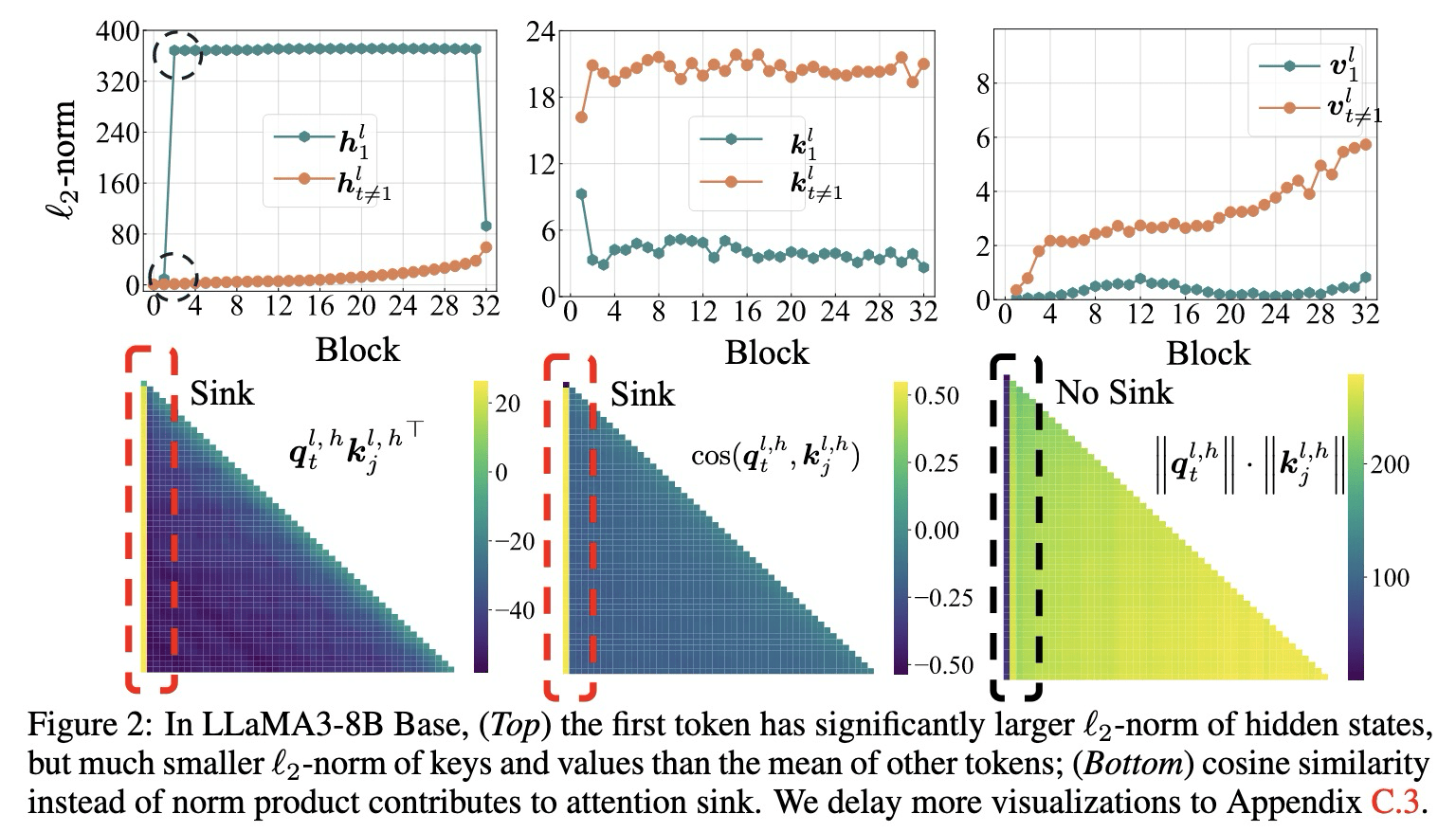
对于第
从 Fig2 的结果可以发现:
- l2 范数的乘积
较小。 - 角度项
非常大,导致了 attention sink。
第一个词符利用其 key 作为偏置(bias),从而最小化
二、Attention Sink 的测量方法
- 基于可视化的方法:绘制出 num_head * num_layers 个图像,难以处理。
- 设计一个观测 attention head 的评估指标。
计算 k-th token 的重要性分数:
首先考虑首 token 的情况。给定阈值
计算 LM 的 attention sink 情况:
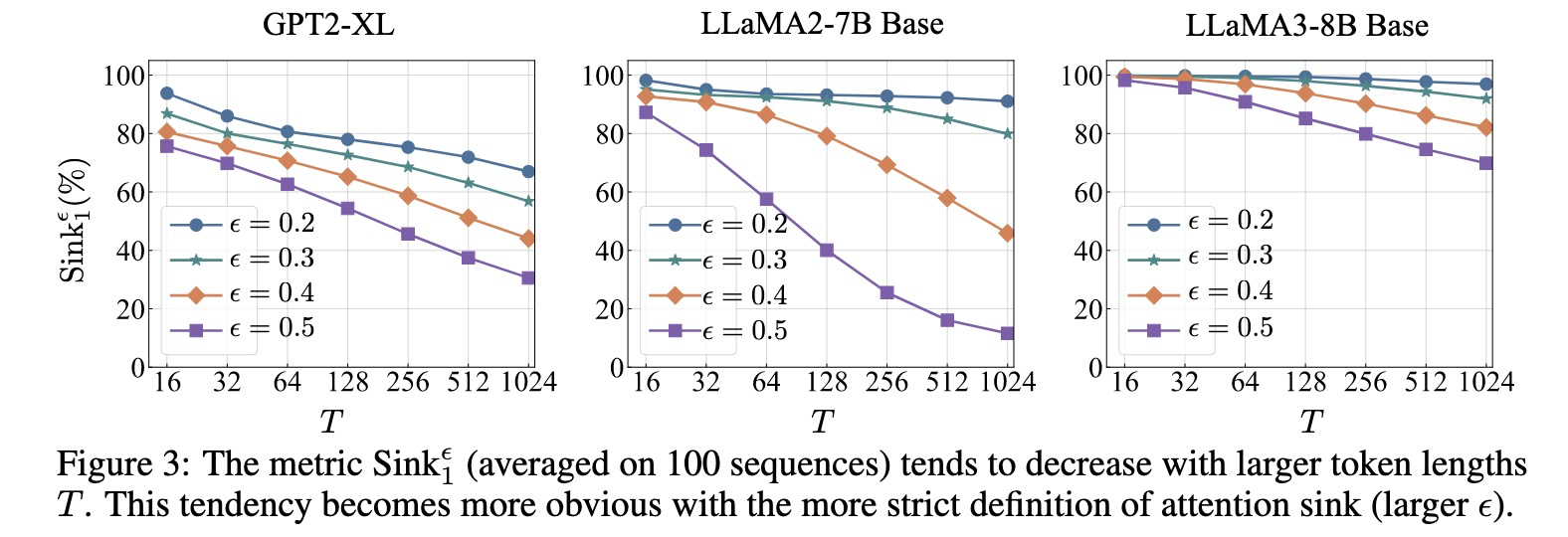
为了不让选择过于严苛,且阈值不对序列长度 T 过于敏感,选择 epsilon=0.3 进行后续分析。
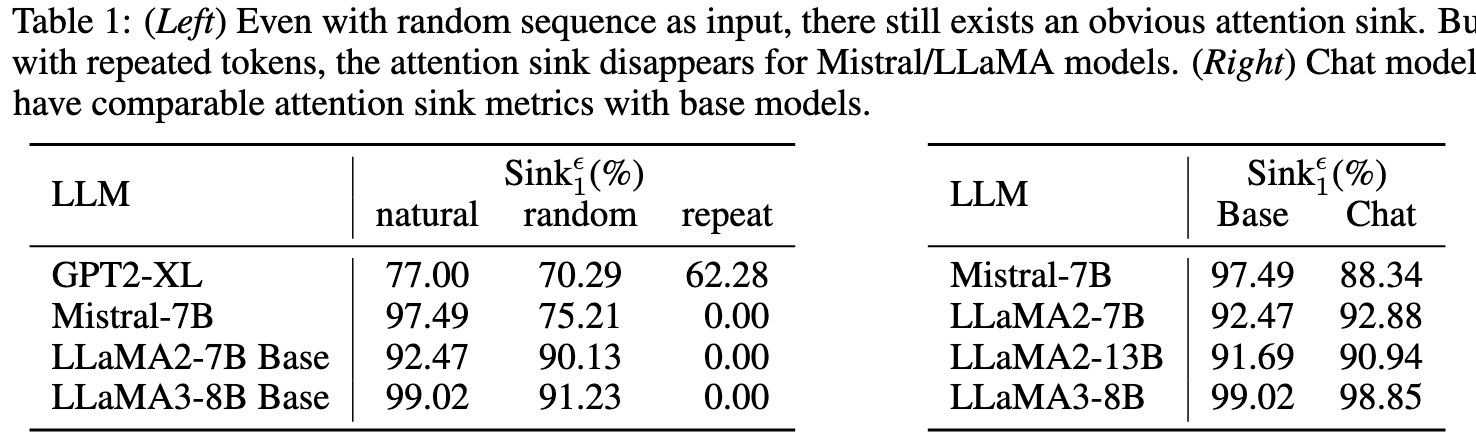
关键特性:
- 输入数据的领域对 attention sink 程度几乎没有影响。
- 超越自然语言:即便输入随机采样的序列也仍会出现。
- base model 和 chat model:经过 instruction tuning 后的模型的 attention sink 结果与预训练模型结果相似。
- model scale:从小模型(14M)到大模型(10B+),attention sink 均会出现。
由于 chat model 和 base model 在 sink 到比例相似,attention sink 很可能是在预训练阶段出现的。
Optimization 对 Attention Sink 的影响
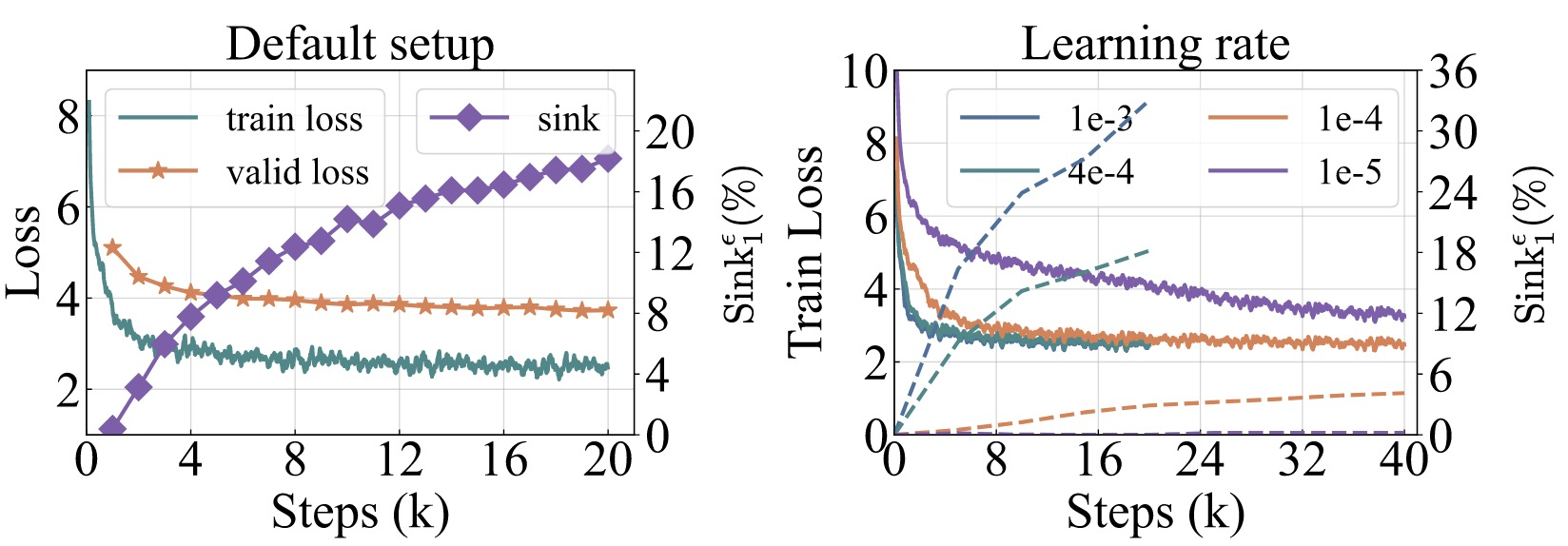 两个核心观察:
两个核心观察:
- 当 LM 经过有效(充分)训练后,attention sink 开始显现。
- 减小学习率可以降低 attention sink 的比例以及增加的速度。
数据分布 P_DATA 对 Attention Sink 的影响
- 当 LM 在充足的训练数据上得到有效训练后,attention sink 开始显现 。
- 通过修改数据分布
,可以将 attention sink 的位置从第一个 token 转移到其他位置。 - 即使将第一个 token 随机重采样,attention sink 依然存在,甚至可能更明显 。
- 如果将输入序列的前几个 token 都进行随机重采样,sink token 的位置可能会发生改变 。
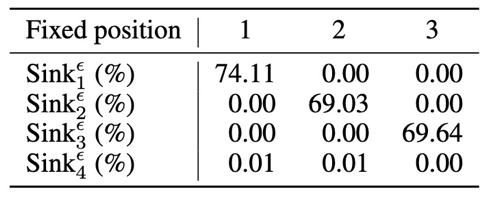
Fix token(StreamingLLM):在序列中添加一个 global learnable token,作为 repository for unnecessary attention scores.
如果为序列添加 fix token,那么 attention sink 会稳定出现在 fix token 所在的位置上。将其移动到其他位置也不会影响结果。
损失函数对 Attention Sink 的影响
weight decay 会促进 attention sink 的出现。
- 即便不用 weight decay,attention sink 仍然会出现,但是增大后 attention sink 会更加明显。
采用 Prefix-LM 时,attention sink 出现在prefix token 中,而不仅仅是第一个 token。
- 仍然只出现在一个 token 上,但这个 token 会是前缀中的某一个,而不是固定在全局的第一个 token。
采用滑动窗口注意力(Shifted Window Attention) 时,attention sink 出现在窗口的“绝对”第一个 token,而非“相对”第一个 token。较小的窗口大小会抑制 sink 的出现。
如果一个 token 位于窗口范围内(即 t≤w,其中 t 为 token 位置,w 为窗口大小),它仍然能够注意到序列的第一个 token,此时模型仍然会在第一个 token 上出现 sink。当 t>w 时,该 token 只能注意到其窗口内的第一个 token(即第 t−w+1 个 token),而这个“相对”的第一个 token 通常不会出现 attention sink。减小窗口大小可以阻止 sink 的出现。
模型结构对 Attention Sink 的影响
位置编码的种类:
- 测试了多种位置编码方式(包括无位置编码 NoPE、绝对位置编码、可学习位置编码、ALiBi 和 RoPE),结果显示,所有采用这些编码方式的语言模型,甚至那些没有明确位置编码的模型,都出现了 attention sink 。
Pre-Norm vs Post-Norm
- Pre-norm:
- Post-norm:
- Pre-norm 结构中,hidden state 的数值可以由 residual connection 在层间传播。一层出现了 massive value 后,后面的层也很有可能保留。
- 无论是 pre-norm 还是 post-norm,attention sink 都会存在。Post-norm 的 massive value 出现在了 Post-LN 之前。
- Pre-norm:
- Attention sink 更像是一种“key bias”

通过引入可学习的 sink token(作为 implicit bias)或直接在注意力机制中添加可学习的键值偏置(KV biases)或仅键偏置(K biases, 此时
Attention 形式的影响
Attention 的一般形式:
对于 Softmax-attention,
设计空间:
- kernel function
:elu plus one; identity; MLP; - 相似度函数
- 是否使用归一化项

结论:当放宽注意力分数之间的内部依赖关系时,attention sink 便不再出现 。
- 允许注意力分数为负数
- 不要求注意力分数归一化为 1
- 使用 MLP 作为 kernel function
不仅如此,在消除掉 attention sink 的同时,massive value 也被消除了。

核心观点和 feature
文章从各个层面,探讨了 attention sink 出现在首 token 时的各种现象,提供了:
- 评估 attention sink 程度的指标
- 优化、数据分布、损失函数、模型结构等对 attention sink 的影响
- 指出 attention sink 的作用类似于一种 key bias,用于储存多余的注意力分数,对计算贡献不大
可能有什么优化方向、有哪些优化的可能
- 使用 attention sink 的评估指标,评估稀疏注意力训练后模型的 attention sink 是否明显。
- 指导稀疏注意力的设计,能否通过通过合理的设计消除掉 sink token。